








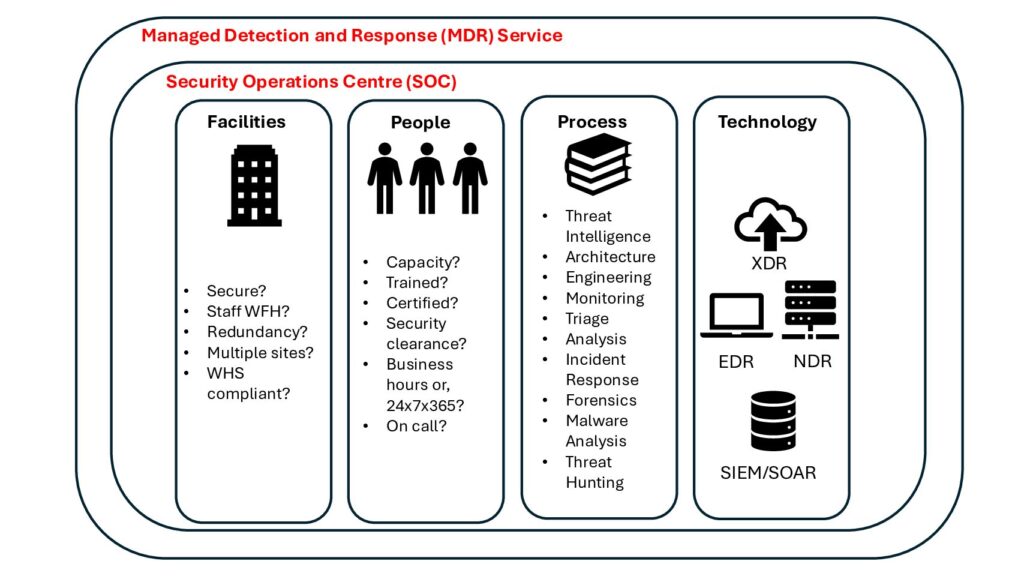
Cyber language – a high level guide to understanding common jargon in Defensive Services
Cyber security has become laden with jargon and terminology, often understood only by a handful of professionals and experts. With…
Read More

